After years of parsing I discovered common structures I used in all sorts of parsers. Some might call these software patterns, or simply data structures and algorithms. When I come across something common, I usually name or label it something catchy, based on what it does.
One of the structures I discovered over and over again (but didn't have a name for) was something I now call a backbuffer. Anything that was scanned passed and saved for later munging around is the backbuffer, while anything that was just recently and immediately scanned passed is the "current buffer".
I found myself calling this occurrence a "temporary buffer that I might use later" or at times a "temporary string that I may need to reference back to later". When a human has long phrases to describe something which are long, he should make an effort to name them or coin a term around the phrase which is more short-form. Short-forms for the bufers I use are Backbuf(s) and Curbuf(s).
I managed to create a horrible diagram for you to see why I think backbuffers are like tapedecks that are recording the main tapedeck that is playing. See the horrible amateur diagram here.
Note that in this article I describe char by char or text by text style parsing and I'm not referring to regular expressions.
A backbuffer is something I keep back in the memory for later use and it acts like a temporary buffer. At times this backbuffer gets flushed out and refreshed with new text. i.e. this buffer can be recycled and reused. Sometimes the backbuffer will remain the same for most of the program, other times it will constantly be recycled.
Aside note for Regex skilled folks:
A backbuffer is similar in someways to a back-reference in regular expressions, because it keeps track of something we came across before that we need later. However a backbuffer is not like a regular expression backreference in many ways, since regular expressions are less powerful than char by char parsers (tapedeck parsers).
You can't stop a regular expression in its tracks and rewind it or pause parsing - the regular expression just blows by the text and grabs whatever you told it to, once over. A regular expression passes over the text once and then you write more regular expressions that pass over the text again. This isn't parsing - this is just glorified find-and-replacing.
In order to understand what a backbuffer is you will have to step outside of regular expression style thinking and put your head into char by char mode, or tapedeck mode.
General Use Case of a Backbuffer
Usually the backbuffer keeps track of some text for later use while you are parsing or even after you are finished parsing. I may use several backbuffers - one backbuffer for all pieces of a certain type of text. I may even use one main backbuffer for a whole bunch of pieces of text of all sorts. I can have as many backbuffers as I want for whatever purpose I want.. they just store something in memory which I may need, and they are generally temporary in nature. They may be changed from temporary to more permanent if I throw them into another variable or structure on hand.
Let's dive right in and I'll give you an example of what I named a backbuffer.
Example: HTML parser Using Backbufs and Curbufs
Consider you are building an HTML parser which is an efficient simple parser that just goes in and finds div tags and text between them. Pretend that you aren't interested in building a full fledged html parser and you don't care about much of the html.. the only thing that interests you for now is the DIV tag. However, you may later need to care about other tags.. so you don't just build a one off regex.. you build a real parser that will be expandable in the future.
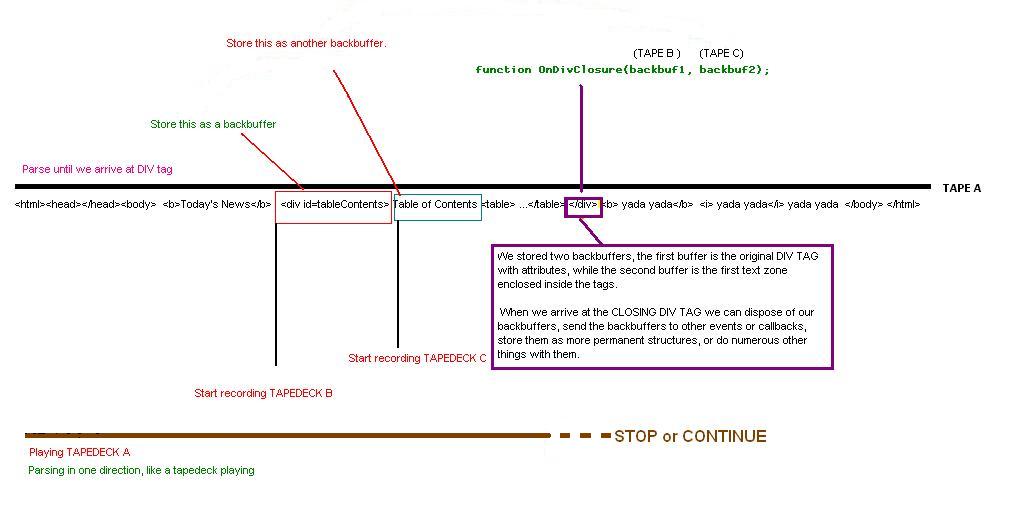
So pretend you are parsing some HTML and you come across an HTML DIV tag. You then want to skip ahead past the html tag and move into the text contents that reside between the open tag and the close tag. Many times you will need to preserve the tag attributes and tag type in a buffer and reference back to it later in a one pass style parser. When you want to deal with the text that is inside the open and close tags you may need to know more details about the type of DIV tag that was used to enclose this text. But since the text follows or proceeds the tag, you have to store the tag in a back buffer.
When I store a temporary piece of text that I've already scanned past with my parser, I call it a backbuffer. In a one-pass style parser these back buffers are very handy so that you don't have to continually research and rescan the data over and over again from position 1.
If I'm trying to find the text between a DIV html tag, but I need to store the DIV tag since it contains attributes that may affect my decisions on what to do with the text, I store the entire DIV tag including attributes in a buffer.. then I continue on. The tag and tag attributes is a backbuffer, while the text between the tags becomes the current buffer. The current buffer may become a backbuffer if I decide it needs to be one - but the current buffer may also be thrown away after processing it. A backbuffer has a longer lifecycle than a current temporary buffer.
The Tapedeck Analogy
I like to think of the parser as the main tape deck, and the back buffers and current buffers as other tape decks that I can record with. The main parser is "TAPE A" while the back buffers and current buffers are "TAPE B", "TAPE C", etc. I can hit the record button on those other tape decks any time I want, and I can even pause TAPE A, the main parser. I can have as many recording tapedecks as I want. Once I hit a position in TapeA of interest, I can hit the record button on TapeB and determine whether TapeB will then turn into a backbuffer or be kept as a current buffer. The backbuffers and current buffers can be sent to events, procedures, callbacks, or they can even be stored more permanently in other global or private structures.
If you store enough useful information, you only have to make one single pass over TapeA (the main file or text snippet), and you shouldn't need to reset it to position 1. If you do have to reset TapeA, it isn't a big deal - but usually it only needs to be reset when the parser becomes very complex.
The advantage of modern computers over oldschool tapedecks and reel to reel machines is that computers can have Pointers to data rather than physical copies of tapes. And in modern programming languages often these pointers are abstract, automatically done for you, like fpc const string parameters [update in 2016: or GoLang slices].
What the backbuffers can do
The backbuffers help you analyze and determine:
- whether or not the current buffer (ahead of the previous buffer) is of any use
- what you are going to do with the current buffer if it offered you new info
- whether or not the current buffer needs to be ignored or reset, if the backbuffer tells you about or relates to the current (latest) buffer
- whether or not other backbuffers need to be ignored or reset
- whether or not other backbuffers need to be overridden or recycled with newly found data in the current buffer.
- whether or not old backbuffers and the current buffer need to be sent to a callback procedure, an event, or stored more permanently in another structure
Sometimes the backbuffers will be stored so that you can send the current buffer and some other backbuffers over to an event or callback procedure. Sometimes the backbuffer tells you that the current buffer you are eating won't be of any interest. Sometimes the backbuffers will be refreshed or reset if you come across the next interesting piece of text that overrides the old backbuffer. Sometimes you will want to store an array of 5 backbuffers instead of just one single previous buffer. Sometimes a backbuffer will be a record (or struct, or class) containing several fields, a more organized backbuffer (i.e. prevtag.HEIGHT and prevtag.WIDTH rather than just a prevtag string containing a stream of raw text data)
Not like Find and Replace
The search and replace style thinking and the regex style thinking leads beginners creating their first parsers to believe that they simply must go over the data several times in order to get what they need. More advanced regex hackers will try and grab important data with one huge regex, and then deal with the data in smaller regexes. This is dangerous since now the programmer may have to design the program to fit the regex, instead of building a parser that fits the needs of the program. It is also dangerous because the programmer has to create large unmaintainable spaghetti regexes.
I've seen the source code to the Smarty Template Engine, and if you look at it you will see exactly what I mean when I say Spagetti Regexes holding the whole code together.
The backbuffer style parsing and the tapedeck style parsing teaches the programmer that he has unlimited power, organization, and flexibility at any time during the parsing. The backbuffer style thinking also teaches the programmer that he should usually not have to go over the data several times in order to get what he needs, unlike with find and replace and regexes.
Backbuffers, Tapedecks, versus Regexes
Tapedeck parsers and backbuffers take more thought and take more code originally than a whipping up a regex though - and in some cases tapedeck parsers and backbuffers are overkill for really small jobs. An example of a small job is you are using your text editor and quickly need to find something fast like all email addresses. You have the option of writing a plugin to do this and loading the DLL for your editor, or you can just open the find/replace dialog and use a regex. Beyond these situations, in my arrogant opinion, regexes are toys for children that cause early brain damage and lead poisoning.
|

{kind=link}